Element Biosciences: Cloudbreak™ Flow Cells Enable Any Application at Any Scale

Scale sample batching, extend read length, or run targeted panels.
Avidity base chemistry (ABC) brings a radically different solution to next-generation sequencing (NGS). Unique to Element Biosciences, ABC innovates each step of sequencing chemistry, separating base detection from strand extension to optimize enzyme conditions for each step to deliver unsurpassed accuracy by ensuring ultrapure base-calling signals while reducing costly reagent consumption. It also generates scarless, natural DNA that confers superior performance over many cycles of sequencing.
The flexibility of selecting from several flow cell configurations based on readlength and throughput needs, allows you the option of running 2x75, 2x150, or 2x300 runs ranging from 100M reads using the 2x300 medium flow cell to 1B reads from the 2x150 or 2x75 flow cells and sequencing kits.
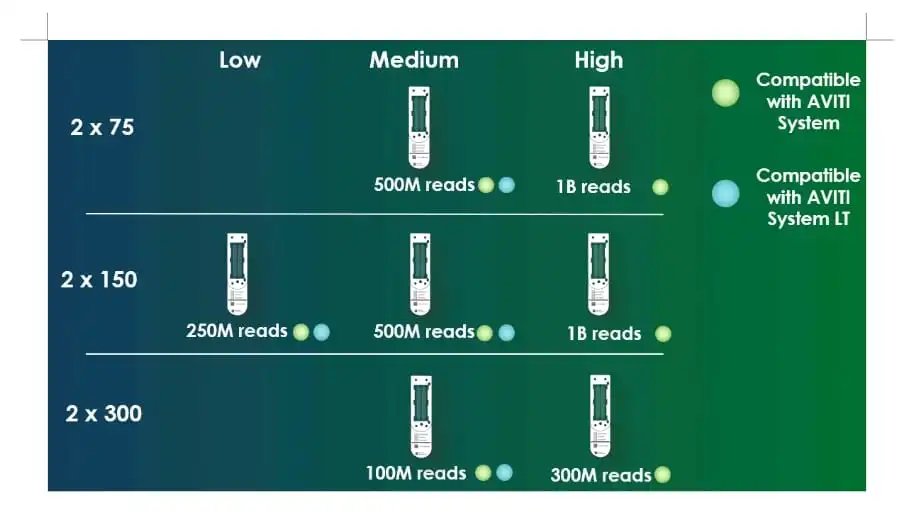
This table illustrates AVITI’s added ability to leverage the high throughput flow cells for each of the three readlength options.
Cloudbreak™ advancements
Cloudbreak is the latest advancement to avidity base chemistry (ABC), scaling to suit any experiment and enhancing operational efficiency in multiple ways:
Increase sequencing speed with 20% faster run times reduce 2 x 150 run times to < 40 hours and single cell experiments in less than a day.
Load a linear library for automatic circularization onboard AVITI.
Sequence and demultiplex Index 1 and Index 2 before Read 1 and Read 2 for real-time quality control and performance feedback.
Improve data quality through the end of each read to enhance accuracy.
Improve sequencing performance through difficult homopolymer regions.
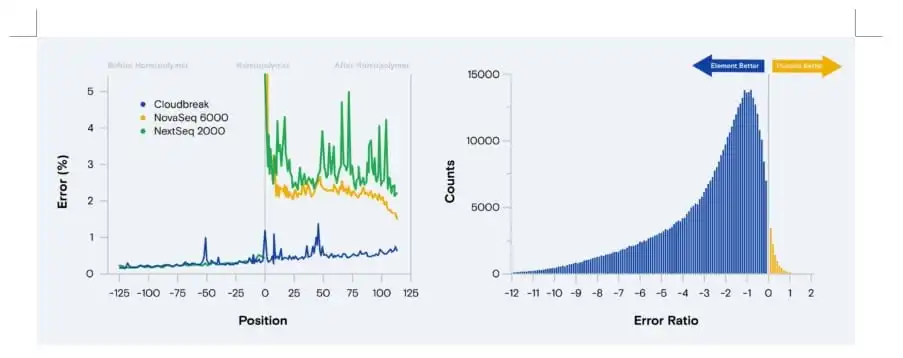
Figure 2. ABC maintains high read quality after crossing a homopolymer at position 0, demonstrating an unaffected error rate versus SBS’s five-fold increase (left). This exceptional performance extends across most long polymers (> 11 bp) in the human genome (right).*
Click here to learn more about how AVITI™ with Cloudbreak is the perfect sequencing solution for you: